配置专用集群用于分布式存储
专用集群部署是指使用独立集群部署平台的分布式存储,平台内其他业务集群通过集成访问并使用该存储提供的服务。
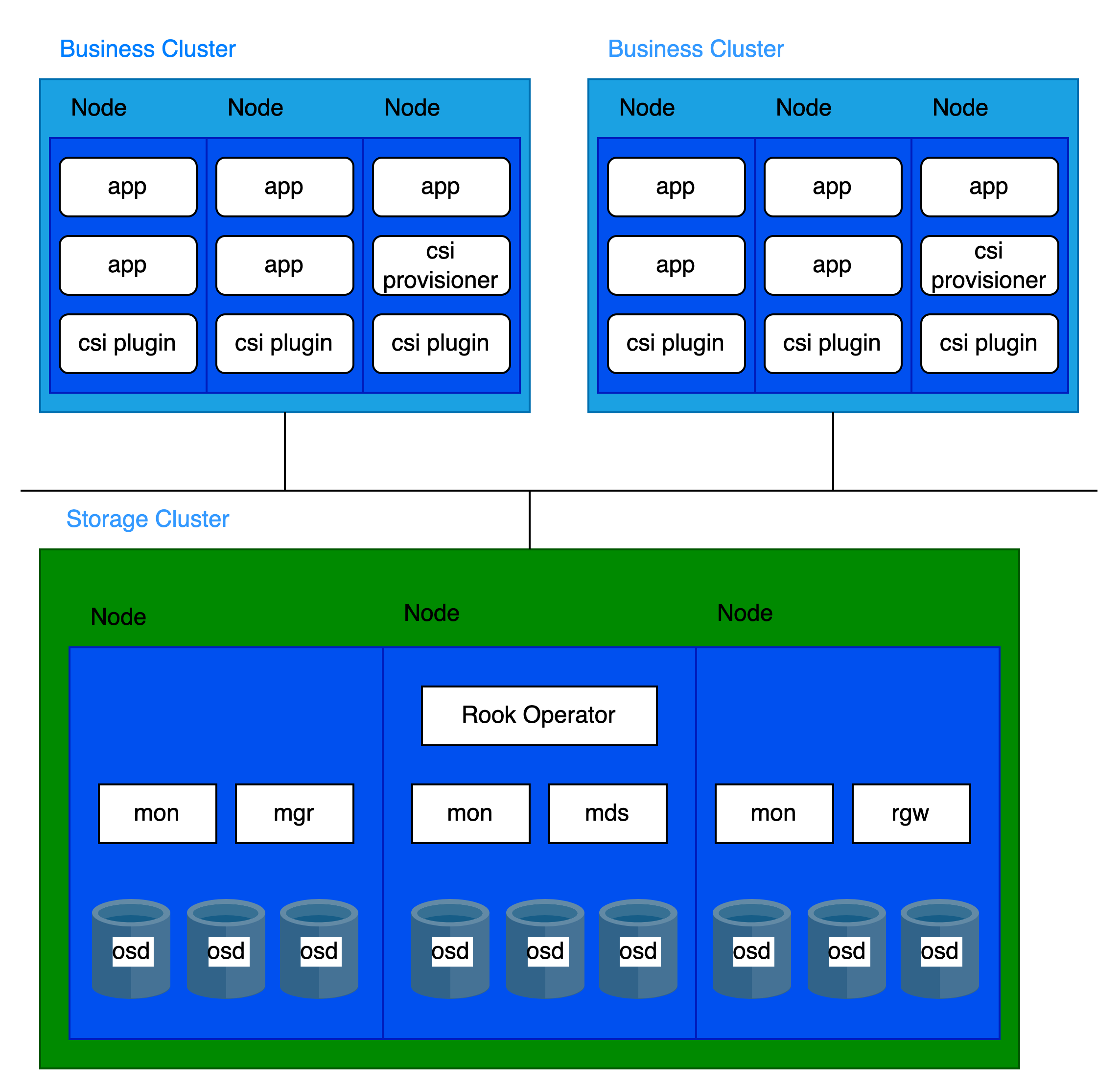
为保证平台分布式存储的性能和稳定性,专用存储集群仅部署平台核心组件和分布式存储组件,避免与其他业务负载混合部署。此种分离部署方式是平台分布式存储的推荐最佳实践。
架构
存储计算分离架构
基础设施要求
平台要求
支持版本为 3.18 及以后版本。
集群要求
建议使用裸金属集群作为专用存储集群。
资源要求
分布式存储部署的组件请参考核心概念。
各组件有不同的 CPU 和内存需求,推荐配置如下:
一个集群通常运行:
- 3 个 MON
- 2 个 MGR
- 多个 OSD
- 2 个 MDS(如果使用 CephFS)
- 2 个 RGW(如果使用 CephObjectStorage)
根据组件分布,单节点资源推荐如下:
存储设备要求
建议每节点部署不超过 12 个存储设备,有助于限制节点故障后的恢复时间。
存储设备类型要求
建议使用企业级 SSD,单个设备容量不超过 10TiB,且所有磁盘大小和类型保持一致。
容量规划
部署前需根据具体业务需求规划存储容量。默认分布式存储系统采用 3 副本冗余策略,因此可用容量为所有存储设备总原始容量除以 3。
以 30(N)节点(副本数 = 3)为例,可用容量示例如下:
容量监控与扩容
-
主动容量规划
始终确保可用存储容量大于消耗容量。存储空间耗尽后,恢复需人工干预,无法通过删除或迁移数据自动解决。
-
容量告警
集群在两个阈值触发告警:
- 80% 利用率(“接近满”):主动释放空间或扩容集群。
- 95% 利用率(“已满”):存储空间完全耗尽,标准命令无法释放空间,请立即联系平台支持。
请务必及时处理告警,定期监控存储使用,避免服务中断。
-
扩容建议
- 避免:向现有节点添加存储设备。
- 推荐:通过新增存储节点进行横向扩展。
- 要求:新增节点存储设备大小、类型和数量需与现有节点保持一致。
网络要求
分布式存储必须使用 HostNetwork。
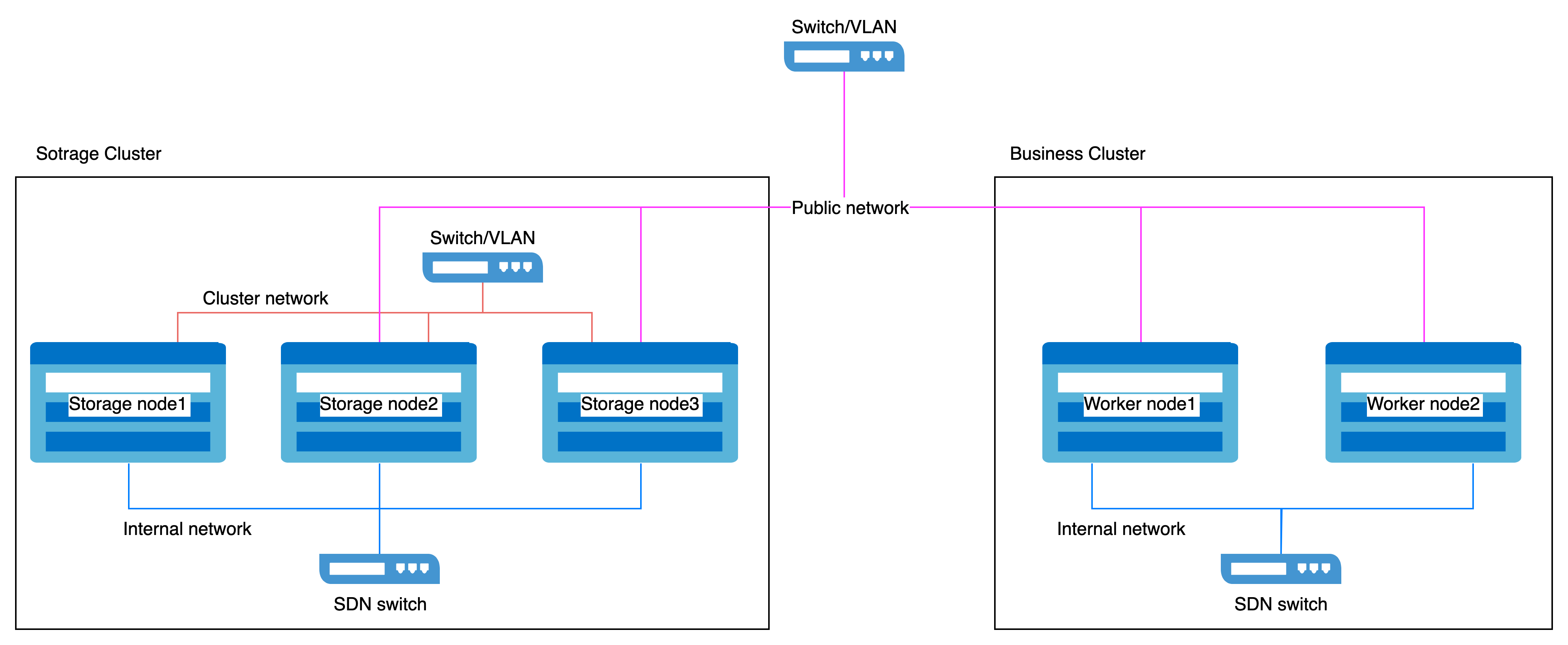
网络隔离
网络分为两类:
- 公网网络:用于客户端与存储组件交互(如 I/O 请求)。
- 集群网络:专用于副本间数据复制及数据均衡(如恢复)。
为保障服务质量和性能稳定:
- 对于专用存储集群:
每台主机预留两个网络接口:- 公网网络:用于客户端和组件通信。
- 集群网络:用于内部复制和均衡流量。
- 对于业务集群:
每台主机预留一个网络接口访问存储公网网络。
示例网络隔离配置
网络接口速率要求
-
存储节点
- 公网网络和集群网络均需 10GbE 或更高速率网络接口。
-
业务集群节点
- 用于访问存储公网网络的网络接口需为 10GbE 或更高。
操作步骤
部署 Operator
-
进入 管理员。
-
在左侧边栏点击 存储管理 > 分布式存储。
-
点击 立即创建。
-
在 部署 Operator 向导页面,点击右下角 部署 Operator 按钮。
- 页面自动跳转下一步表示 Operator 部署成功。
- 若部署失败,请根据界面提示选择 清理已部署信息并重试,重新部署 Operator;若需返回分布式存储选择页,点击 应用商店,先卸载已部署的 rook-operator 资源,再卸载 rook-operator。
创建 ceph 集群
在存储集群的 控制节点 执行命令。
点击查看
参数说明:
- public network cidr:存储公网网络的 CIDR(例如
- 10.0.1.0/24)。 - cluster network cidr:存储集群网络的 CIDR(例如
- 10.0.2.0/24)。 - storage devices:指定分布式存储使用的存储设备。
示例格式:提示使用磁盘的全球唯一名称(WWN)进行稳定命名,避免依赖如
sdb这类重启后可能变化的设备路径。
创建存储池
提供三种存储池类型,根据业务需求选择创建。
创建文件池
在存储集群的 控制节点 执行命令。
点击查看
创建块池
在存储集群的 控制节点 执行命令。
点击查看
创建对象池
在存储集群的 控制节点 执行命令。
点击查看
后续操作
当其他集群需要使用分布式存储服务时,请参考以下指南。
访问存储服务