架构
Alauda Distributed Tracing 基于 Jaeger v2 和 Alauda Build of OpenTelemetry v2。Jaeger 实例通过 OpenTelemetry Operator 部署,并使用 Elasticsearch 或 OpenSearch 作为后端存储。在这种架构中,Jaeger v2 为数据摄取、查询和可视化提供核心链路追踪后端能力。
Jaeger v2 旨在成为一个多功能且灵活的链路追踪平台。它可以以单一二进制程序的形式部署,并配置为在 Jaeger 架构中执行不同的 角色。
目录
角色存储架构直接写入存储使用 OpenTelemetry Collector作为 sidecar / 主机代理的 OpenTelemetry Collector作为远程集群的 OpenTelemetry CollectorJaeger 二进制程序Jaeger 组件OpenTelemetry 组件接收器处理器导出器连接器扩展角色
- collector:接收来自应用程序的传入 trace 数据,并将其写入存储后端。
- query:提供用于查询和可视化 trace 的 API 和用户界面。
- es-rollover:管理 Jaeger 的基于 Elasticsearch rollover 的索引操作。它用于为 rollover 部署准备 alias、index 和 template,并可以在更新 read alias 的同时,定期将 write alias 切换到新的 index。
- es-index-cleaner:删除早于配置保留期的按时间划分的索引。它会匹配带日期后缀的索引(
<prefix>-jaeger-(span|service|dependencies|sampling)-YYYY-MM-DD),并移除超过保留阈值的索引。它通常与 OpenSearch 部署一起使用,这类部署依赖按天索引而不是 rollover alias,以强制执行 trace 数据保留策略。
存储架构
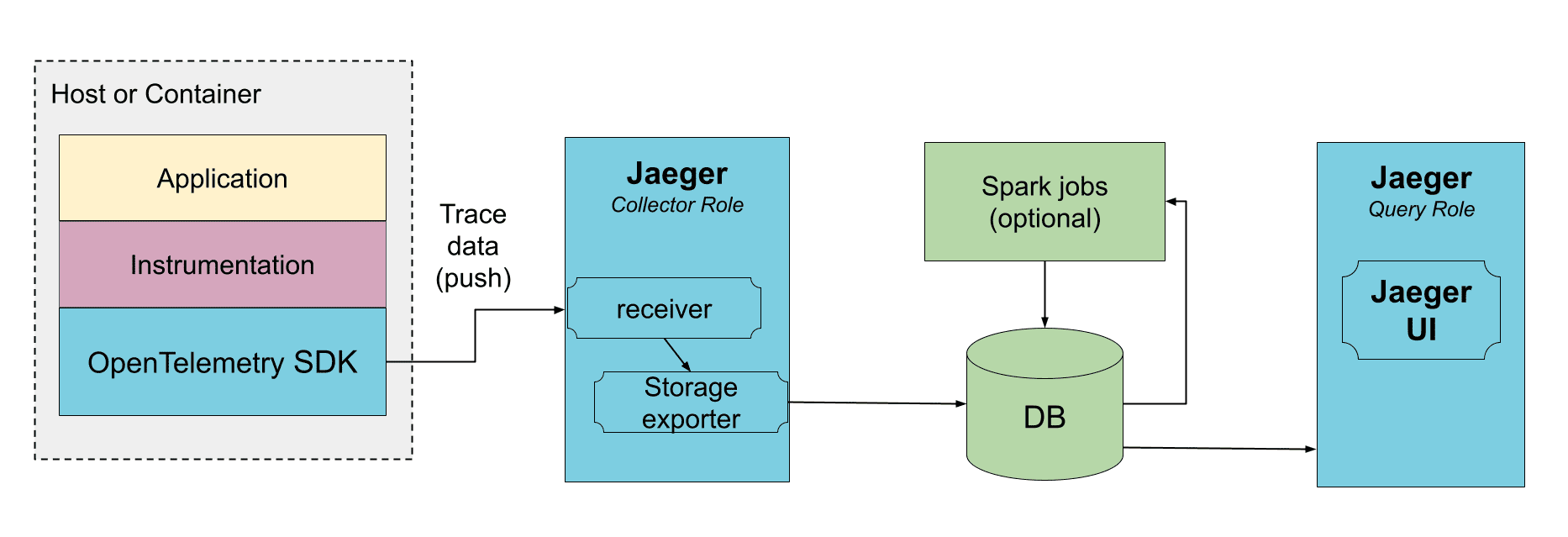
直接写入存储
在此部署中,collector 从被追踪的应用接收数据,并直接写入存储。存储必须能够同时处理平均流量和峰值流量。collector 可以使用内存队列来平滑短期流量峰值,但如果存储无法跟上,持续的流量突增可能会导致数据丢失。
使用 OpenTelemetry Collector
你不需要使用 OpenTelemetry Collector 来运行 Jaeger,因为 Jaeger 是 OpenTelemetry Collector 的定制发行版,并具有不同的角色。但是,如果你已经在使用 OpenTelemetry Collectors 来收集其他类型的遥测,或对 trace 数据进行预处理/增强,那么它可以放在 Jaeger 的收集流水线前端。OpenTelemetry Collector 可以作为应用 sidecar 运行,也可以作为远程服务集群运行。
OpenTelemetry Collector 支持 Jaeger 的 Remote Sampling 协议,既可以直接从配置文件提供静态配置,也可以将请求代理到 Jaeger 后端(例如在使用自适应采样时)。
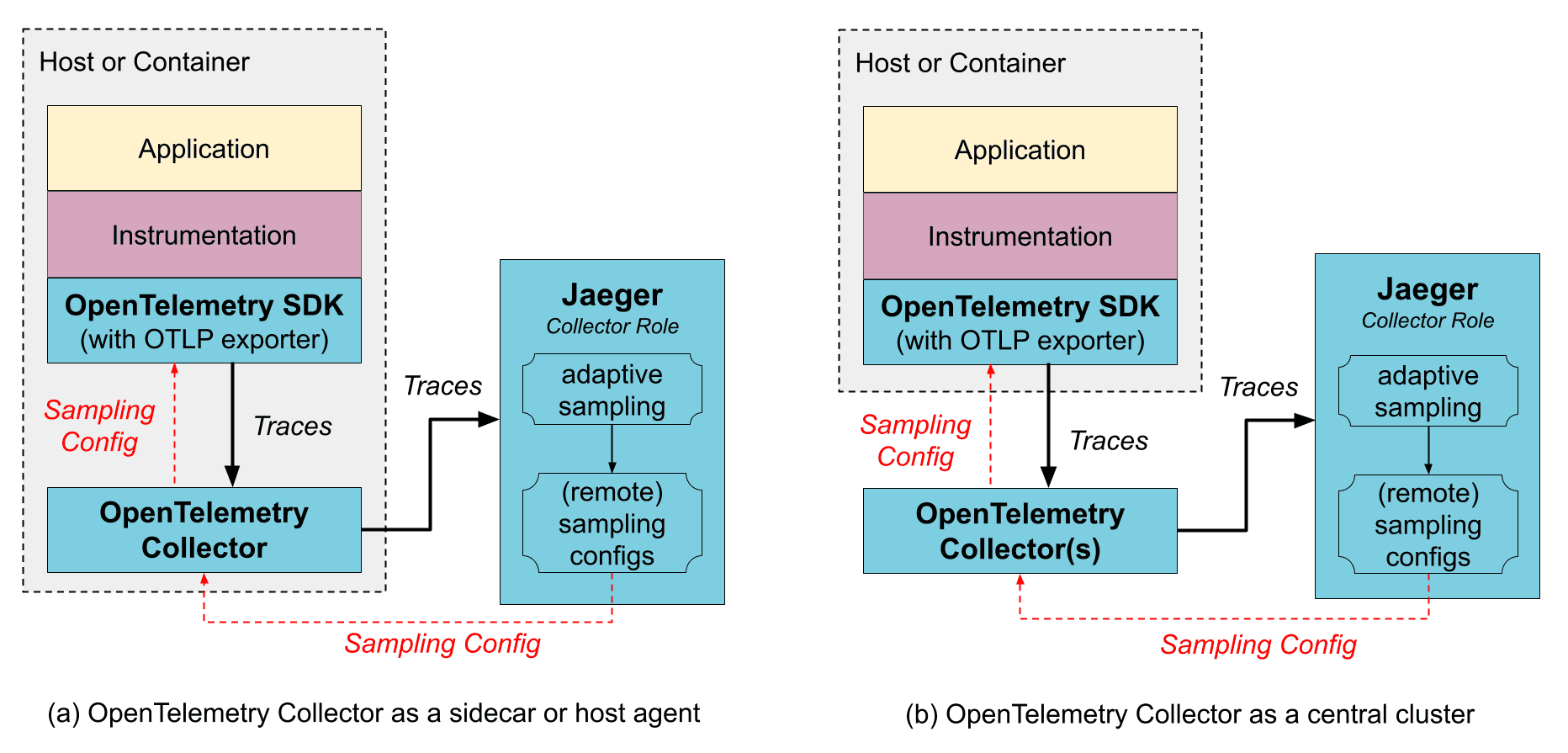
作为 sidecar / 主机代理的 OpenTelemetry Collector
优点:
- SDK 配置更简单,因为 trace 导出端点和采样配置端点都可以指向本地主机,而无需关心这些服务在远程运行的位置。
- Collector 可以通过添加环境信息(例如 k8s pod name)来提供数据增强。
- 数据增强所需的资源可以分散到所有应用主机上。
缺点:
- 数据会额外经历一层编组/解组。
作为远程集群的 OpenTelemetry Collector
优点:
- 具备分片能力,例如在使用 尾部采样 时。
缺点:
- 数据会额外经历一层编组/解组。
Jaeger 二进制程序
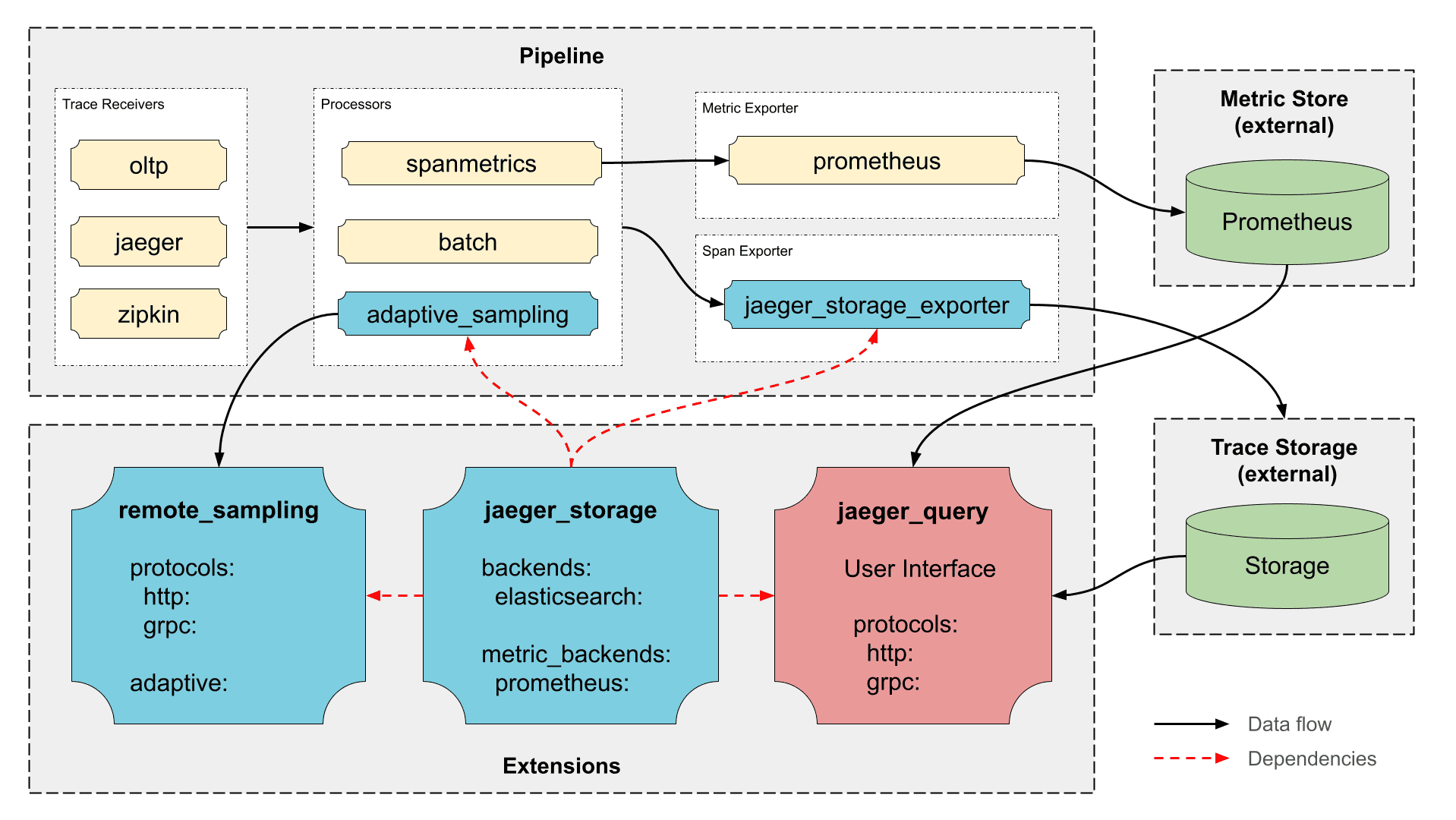
Jaeger 二进制程序构建于 OpenTelemetry Collector framework 之上,并包括:
- 官方上游组件,例如 OTLP Receiver、Batch 和 Attribute Processor 等。
- 来自
opentelemetry-collector-contrib的上游组件,例如 Kafka Exporter 和 Receiver、Tail Sampling Processor 等。 - Jaeger 自身组件,例如 Jaeger Storage Exporter、Jaeger Query Extension 等。
Jaeger 组件
- Jaeger 存储扩展 - Jaeger 中支持的存储后端的可扩展枢纽。它为其他所有 Jaeger 组件提供访问 Jaeger 存储实现的能力。
- Jaeger 存储导出器 - 将 span 写入在 Jaeger Storage Extension 中配置的存储后端。
- Jaeger 查询扩展 - 运行查询 API 和 Jaeger UI。
- 自适应采样处理器 - 执行自适应采样的概率计算。
- 远程采样扩展 - 基于静态配置文件或自适应采样提供 Remote Sampling 端点。
OpenTelemetry 组件
接收器
- OTLP - 接受通过 OpenTelemetry Protocol (OTLP) 发送的 span。
- Jaeger - 接受通过 gRPC 或 Thrift 协议传输的 Jaeger 格式 trace。
- Kafka - 接受来自 Kafka 的多种格式 span(OTLP、Jaeger、Zipkin)。
- Zipkin - 接受使用 Zipkin v1 和 v2 协议的 span。
- No-op - 用于不需要摄取流水线的 Jaeger UI / query 服务部署。
处理器
- Batch 处理器 - 对 span 进行批处理,以提高效率。
- 尾部采样 - 支持高级的采集后采样。
- 内存限制器 - 在 collector 过载时支持反压。
- 属性处理器 - 允许使用属性对 span 进行过滤、重写和增强。可用于屏蔽敏感数据、减少数据量或附加环境信息。
- 过滤处理器 - 允许从 collector 中丢弃 span 和 span event(⚠️ 可能导致 trace 断裂)。
导出器
- OTLP - 通过 gRPC 以 OTLP 格式发送数据。
- OTLP HTTP - 通过 HTTP 以 OTLP 格式发送数据。
- Kafka - 以多种格式(OTLP、Jaeger、Zipkin)将数据发送到 Kafka。
- Prometheus - 将指标发送到 Prometheus。
- Debug - 用于管道调试的工具。
- No-op - 用于不需要摄取流水线的 Jaeger UI / query 服务部署。
连接器
扩展
- 健康检查 v2 - 支持健康检查。
- zPages - 暴露 collector 的内部状态以便调试。
- 性能分析器 (pprof) - 启用 Go 的
net/http/pprof端点,通常由开发人员用于收集性能分析信息并排查 collector 的问题。