配置 Egress Gateway
概述
Egress Gateway,也称为 VPC Egress Gateway,为 overlay 网络中的 Pods 提供稳定的出站地址。
它会在流量离开集群之前,将选定的工作负载通过专用的网关 Pods 进行转发。
在以下场景中使用 Egress Gateway:
- 为特定工作负载提供稳定的源 IP 地址
- 需要按工作负载级别进行出站控制,而不是按子网级别控制
- 通过水平扩展获得更高吞吐量
- 需要更快的出站流量故障切换
主要能力:
- 通过 ECMP 实现 Active-Active 高可用,并支持水平吞吐量扩展
- 通过 BFD 实现快速故障切换,通常少于 1 秒
- 支持 IPv4、IPv6 和双栈环境
- 通过 NamespaceSelector 和 PodSelector 实现细粒度流量匹配
- 通过 node selectors 和 tolerations 实现灵活调度
当前限制:
- 多副本部署需要多个 egress IP
- 不保留源 NAT 映射记录
Egress Gateway 与集中式网关对比
使用本节选择最适合你的场景的网关模式。
有关集中式模式的详细信息,请参阅 配置集中式网关。
选择建议:
- 当你需要工作负载级策略控制、可扩展吞吐量和快速故障切换时,选择 Egress Gateway。
- 当子网级固定出站和简单运维已足够时,选择 集中式网关。
Egress Gateway 的工作原理
Egress Gateway 以一个或多个 Pods 的形式运行。每个 Pod 使用两个网络接口:
- 一个接口连接到集群内部的 overlay 网络。
- 另一个接口连接到外部 underlay 网络。
来自选定 Pods 的流量会先转发到网关 Pods,然后通过 underlay 接口发送到外部网络。
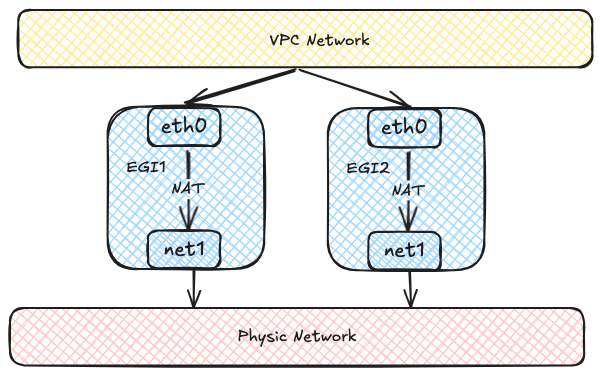
每个 Egress Gateway 实例都会在 OVN 路由表中注册其地址。
当 overlay 网络中的 Pod 访问外部网络时,OVN 使用源地址哈希将流量分配到多个网关实例。
这提供了负载均衡,并且随着实例数量增加,可以水平扩展吞吐量。
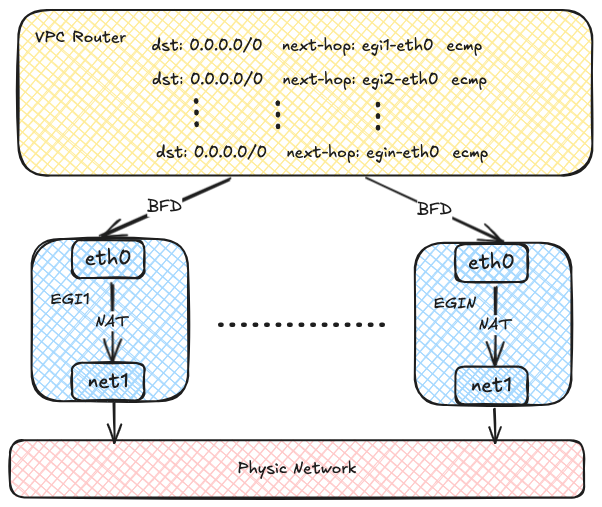
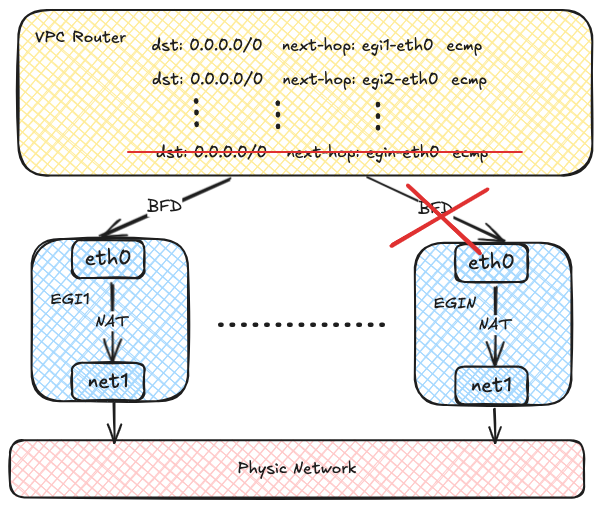
OVN 可以使用 BFD 探测多个网关实例。
如果某个实例发生故障,OVN 会将对应路由标记为不可用,并快速将流量重定向到健康实例。
开始之前
在开始之前,请确保满足以下前提条件:
- 集群中已经安装 Multus CNI Plugin,且必须已就绪。
- 外部 underlay 网络、VLAN 和 bridge 网络已经规划并可用。
- 你已经确定哪些工作负载应使用网关,以及它们是否需要 SNAT。
有关安装 Multus CNI Plugin,请参阅 部署 Multus CNI Plugin。
配置流程
按以下顺序配置 Egress Gateway:
- 准备外部网络挂载,包括子网和 Network Attachment Definition。
- 创建 VPC Egress Gateway 资源,并指定外部子网和策略。
- 验证资源状态、路由和流量转发。
- 可选地扩展副本数并启用基于 BFD 的快速故障切换。
步骤 1:准备外部网络挂载
Egress Gateway 使用多个接口同时连接内部和外部网络。
在创建网关之前,请准备以下资源:
- 一个外部子网
- 该子网对应的 Network Attachment Definition(NAD)
以下示例使用 Kube-OVN underlay 子网作为外部网络。
NOTE
此示例假定 bridge 网络和 VLAN 资源 external-vlan 已为 underlay 网络创建完成。
apiVersion: k8s.cni.cncf.io/v1
kind: NetworkAttachmentDefinition
metadata:
name: underlay-ext
namespace: default
spec:
config: |-
{
"cniVersion": "0.3.0",
"type": "kube-ovn",
"server_socket": "/run/openvswitch/kube-ovn-daemon.sock",
"provider": "underlay-ext.default.ovn"
}
---
apiVersion: kubeovn.io/v1
kind: Subnet
metadata:
name: underlay-ext
spec:
protocol: IPv4
provider: underlay-ext.default.ovn
cidrBlock: 172.17.0.0/16
gateway: 172.17.0.1
vlan: external-vlan
excludeIps:
- 172.17.0.11..172.17.0.20
- Secondary network 使用的 Kube-OVN CNI plugin。
- CNI plugin 使用的 Kube-OVN daemon socket。
- provider 名称,格式为
<network attachment definition name>.<namespace>.ovn。
- 该子网使用的 provider。此值必须与 NetworkAttachmentDefinition 中的 provider 一致。
- 外部 underlay 网络的 CIDR。
- 外部 underlay 网络的网关。
- underlay 子网使用的 VLAN 资源。
- 从自动分配中排除的 IP 范围。详情请参阅 使用 Kube-OVN Underlay 网络的示例子网自定义资源(CR)。
步骤 2:创建 VPC Egress Gateway
创建一个 VPC Egress Gateway 资源,并定义哪些工作负载应使用它。
apiVersion: kubeovn.io/v1
kind: VpcEgressGateway
metadata:
name: gateway1
namespace: default
spec:
replicas: 1
internalSubnet: ovn-default
externalSubnet: underlay-ext
externalIPs:
- 172.17.0.11
- 172.17.0.12
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 200m
memory: 256Mi
ephemeral-storage: 2Gi
nodeSelector:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node1
- node2
tolerations:
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
selectors:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: ns1
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: ns2
podSelector:
matchLabels:
app: myapp
policies:
- snat: true
subnets:
- subnet1
- snat: false
ipBlocks:
- 10.18.0.0/16
- 创建 VPC Egress Gateway 实例的 Namespace。
- VPC Egress Gateway 实例数量。
- 连接到内部网络的内部子网。该子网必须是同一 VPC 中的 overlay 子网,并且要有足够的空闲 IP 供网关实例使用。
如果未指定,网关 Pods 将使用该 VPC 的默认内部子网。
- 连接到外部网络的外部子网。
- 网关 Pods 在 underlay 网络上使用的外部 IP。每个网关实例会从该列表中分配一个 IP。
这些 IP 必须位于外部子网的 CIDR 内,并且应包含在子网的
excludeIps 范围中。
建议预留 .spec.replicas + 1 个 IP,以便在边缘情况下网关 Pod 仍可获得 IP。
- 每个 VPC Egress Gateway 实例的资源请求和限制。
如果未指定,将应用 VPC Egress Gateway controller 中定义的默认资源请求和限制。
- 用于调度 VPC Egress Gateway 实例的 node selectors。
- 用于调度 VPC Egress Gateway 实例的 tolerations。
- 用于选择通过 VPC Egress Gateway 访问外部网络的 Pods 的 Namespace selectors 和 Pod selectors。
- VPC Egress Gateway 的策略,包括要应用的 SNAT 和 subnets/ipBlocks。
- 是否为该策略启用 SNAT。
- 该策略适用的子网。
- 该策略适用的 IP block。
此示例在 default Namespace 中创建了一个名为 gateway1 的 VPC Egress Gateway。
与 selectors 和 policies 匹配的流量会通过外部子网 underlay-ext 转发。
在此示例中,包括:
- ns1 Namespace 中的 Pods
- 带有标签
app: myapp 的 ns2 Namespace 中的 Pods
- 与 subnet1 子网相关的流量
- 与 CIDR 10.18.0.0/16 相关的流量
NOTE
匹配 .spec.selectors 的 Pods 始终会由网关执行 SNAT。
步骤 3:验证网关
创建网关后,确认它已就绪并且按预期转发流量。
1. 检查资源状态
先查看基础资源状态:
$ kubectl get veg gateway1
NAME VPC REPLICAS BFD ENABLED EXTERNAL SUBNET PHASE READY AGE
gateway1 ovn-cluster 1 false underlay-ext Completed true 13s
然后查看网关的详细信息:
kubectl get veg gateway1 -o wide
NAME VPC REPLICAS BFD ENABLED EXTERNAL SUBNET PHASE READY INTERNAL IPS EXTERNAL IPS WORKING NODES AGE
gateway1 ovn-cluster 1 false underlay-ext Completed true ["10.16.0.12"] ["172.17.0.11"] ["node1"] 82s
最后,验证网关工作负载正在运行:
$ kubectl get deployment -n default -l ovn.kubernetes.io/vpc-egress-gateway=gateway1
NAME READY UP-TO-DATE AVAILABLE AGE
gateway1 1/1 1 1 4m40s
$ kubectl get pod -n default -l ovn.kubernetes.io/vpc-egress-gateway=gateway1 -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
gateway1-b9f8b4448-76lhm 1/1 Running 0 4m48s 10.16.0.12 node1 <none> <none>
2. 检查网关 Pod 内部网络
检查网关 Pod 内的 IP 地址、路由条目和 iptables 规则:
$ kubectl exec -n default gateway1-b9f8b4448-76lhm -c gateway -- ip address show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: net1@if13: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 62:d8:71:90:7b:86 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.11/16 brd 172.17.255.255 scope global net1
valid_lft forever preferred_lft forever
inet6 fe80::60d8:71ff:fe90:7b86/64 scope link
valid_lft forever preferred_lft forever
17: eth0@if18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1400 qdisc noqueue state UP group default
link/ether 36:7c:6b:c7:82:6b brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.16.0.12/16 brd 10.16.255.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::347c:6bff:fec7:826b/64 scope link
valid_lft forever preferred_lft forever
$ kubectl exec -n default gateway1-b9f8b4448-76lhm -c gateway -- ip rule show
0: from all lookup local
1001: from all iif eth0 lookup default
1002: from all iif net1 lookup 1000
1003: from 10.16.0.12 iif lo lookup 1000
1004: from 172.17.0.11 iif lo lookup default
32766: from all lookup main
32767: from all lookup default
$ kubectl exec -n default gateway1-b9f8b4448-76lhm -c gateway -- ip route show
default via 172.17.0.1 dev net1
10.16.0.0/16 dev eth0 proto kernel scope link src 10.16.0.12
10.17.0.0/16 via 10.16.0.1 dev eth0
10.18.0.0/16 via 10.16.0.1 dev eth0
172.17.0.0/16 dev net1 proto kernel scope link src 172.17.0.11
$ kubectl exec -n default gateway1-b9f8b4448-76lhm -c gateway -- ip route show table 1000
default via 10.16.0.1 dev eth0
$ kubectl exec -n default gateway1-b9f8b4448-76lhm -c gateway -- iptables -t nat -S
-P PREROUTING ACCEPT
-P INPUT ACCEPT
-P OUTPUT ACCEPT
-P POSTROUTING ACCEPT
-N VEG-MASQUERADE
-A PREROUTING -i eth0 -j MARK --set-xmark 0x4000/0x4000
-A POSTROUTING -d 10.18.0.0/16 -j RETURN
-A POSTROUTING -s 10.18.0.0/16 -j RETURN
-A POSTROUTING -j VEG-MASQUERADE
-A VEG-MASQUERADE -j MARK --set-xmark 0x0/0xffffffff
-A VEG-MASQUERADE -j MASQUERADE --random-fully
3. 确认流量转发
在网关 Pod 中抓包,确认流量通过网关转发:
$ kubectl exec -n default gateway1-b9f8b4448-76lhm -c gateway -- tcpdump -i any -nnve icmp and host 172.17.0.1
tcpdump: data link type LINUX_SLL2
tcpdump: listening on any, link-type LINUX_SLL2 (Linux cooked v2), snapshot length 262144 bytes
06:50:58.936528 eth0 In ifindex 17 92:26:b8:9e:f2:1c ethertype IPv4 (0x0800), length 104: (tos 0x0, ttl 63, id 30481, offset 0, flags [DF], proto ICMP (1), length 84)
10.17.0.9 > 172.17.0.1: ICMP echo request, id 37989, seq 0, length 64
06:50:58.936574 net1 Out ifindex 2 62:d8:71:90:7b:86 ethertype IPv4 (0x0800), length 104: (tos 0x0, ttl 62, id 30481, offset 0, flags [DF], proto ICMP (1), length 84)
172.17.0.11 > 172.17.0.1: ICMP echo request, id 39449, seq 0, length 64
06:50:58.936613 net1 In ifindex 2 02:42:39:79:7f:08 ethertype IPv4 (0x0800), length 104: (tos 0x0, ttl 64, id 26701, offset 0, flags [none], proto ICMP (1), length 84)
172.17.0.1 > 172.17.0.11: ICMP echo reply, id 39449, seq 0, length 64
06:50:58.936621 eth0 Out ifindex 17 36:7c:6b:c7:82:6b ethertype IPv4 (0x0800), length 104: (tos 0x0, ttl 63, id 26701, offset 0, flags [none], proto ICMP (1), length 84)
172.17.0.1 > 10.17.0.9: ICMP echo reply, id 37989, seq 0, length 64
4. 确认 OVN 路由策略
系统会自动为选定流量创建 OVN Logical Router policies:
$ kubectl ko nbctl lr-policy-list ovn-cluster
Routing Policies
31000 ip4.dst == 10.16.0.0/16 allow
31000 ip4.dst == 10.17.0.0/16 allow
31000 ip4.dst == 100.64.0.0/16 allow
30000 ip4.dst == 172.18.0.2 reroute 100.64.0.4
30000 ip4.dst == 172.18.0.3 reroute 100.64.0.3
30000 ip4.dst == 172.18.0.4 reroute 100.64.0.2
29100 ip4.src == $VEG.8ca38ae7da18.ipv4 reroute 10.16.0.12
29100 ip4.src == $VEG.8ca38ae7da18_ip4 reroute 10.16.0.12
29000 ip4.src == $ovn.default.kube.ovn.control.plane_ip4 reroute 100.64.0.3
29000 ip4.src == $ovn.default.kube.ovn.worker2_ip4 reroute 100.64.0.2
29000 ip4.src == $ovn.default.kube.ovn.worker_ip4 reroute 100.64.0.4
29000 ip4.src == $subnet1.kube.ovn.control.plane_ip4 reroute 100.64.0.3
29000 ip4.src == $subnet1.kube.ovn.worker2_ip4 reroute 100.64.0.2
29000 ip4.src == $subnet1.kube.ovn.worker_ip4 reroute 100.64.0.4
- VPC Egress Gateway 用于转发与 .spec.policies 匹配流量的 Logical Router Policy。
- VPC Egress Gateway 用于转发与 .spec.selectors 匹配流量的 Logical Router Policy。
可选:启用多副本负载均衡
NOTE
在扩展副本之前,请确保在外部子网中准备足够的外部 IP,并将它们指定到 .spec.externalIPs 中。
要启用 ECMP 负载均衡并横向扩展吞吐量,请增加 .spec.replicas:
$ kubectl scale veg -n default gateway1 --replicas=2
vpcegressgateway.kubeovn.io/gateway1 scaled
$ kubectl get veg -n default gateway1
NAME VPC REPLICAS BFD ENABLED EXTERNAL SUBNET PHASE READY AGE
gateway1 ovn-cluster 2 false underlay-ext Completed true 39m
$ kubectl get pod -n default -l ovn.kubernetes.io/vpc-egress-gateway=gateway1 -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
gateway1-b9f8b4448-76lhm 1/1 Running 0 40m 10.16.0.12 node1 <none> <none>
gateway1-b9f8b4448-zd4dl 1/1 Running 0 64s 10.16.0.13 node2 <none> <none>
$ kubectl ko nbctl lr-policy-list ovn-cluster
Routing Policies
31000 ip4.dst == 10.16.0.0/16 allow
31000 ip4.dst == 10.17.0.0/16 allow
31000 ip4.dst == 100.64.0.0/16 allow
30000 ip4.dst == 172.18.0.2 reroute 100.64.0.4
30000 ip4.dst == 172.18.0.3 reroute 100.64.0.3
30000 ip4.dst == 172.18.0.4 reroute 100.64.0.2
29100 ip4.src == $VEG.8ca38ae7da18.ipv4 reroute 10.16.0.12, 10.16.0.13
29100 ip4.src == $VEG.8ca38ae7da18_ip4 reroute 10.16.0.12, 10.16.0.13
29000 ip4.src == $ovn.default.kube.ovn.control.plane_ip4 reroute 100.64.0.3
29000 ip4.src == $ovn.default.kube.ovn.worker2_ip4 reroute 100.64.0.2
29000 ip4.src == $ovn.default.kube.ovn.worker_ip4 reroute 100.64.0.4
29000 ip4.src == $subnet1.kube.ovn.control.plane_ip4 reroute 100.64.0.3
29000 ip4.src == $subnet1.kube.ovn.worker2_ip4 reroute 100.64.0.2
29000 ip4.src == $subnet1.kube.ovn.worker_ip4 reroute 100.64.0.4
可选:启用基于 BFD 的高可用
基于 BFD 的故障切换依赖 VPC BFD LRP。
请按以下顺序启用。
1. 为 VPC 启用 BFD Port
首先,为 VPC 启用 BFD Port:
apiVersion: kubeovn.io/v1
kind: Vpc
metadata:
name: ovn-cluster
spec:
bfdPort:
enabled: true
ip: 10.255.255.255
nodeSelector:
matchLabels:
kubernetes.io/os: linux
- 是否启用 BFD Port。
- BFD Port 的 IP 地址,必须是一个有效 IP,且不能与任何其他 IP/Subnet 冲突。
- 用于选择运行 Active-Backup 模式下 BFD Port 的节点的 node selector。
TIP
Vpc 资源 ovn-cluster 默认已存在。你可以直接编辑它以启用 BFD Port。
启用 BFD Port 后,会在 OVN Logical Router 上自动创建一个专用的 BFD LRP:
$ kubectl ko nbctl show ovn-cluster
router 0c1d1e8f-4c86-4d96-88b2-c4171c7ff824 (ovn-cluster)
port bfd@ovn-cluster
mac: "8e:51:4b:16:3c:90"
networks: ["10.255.255.255"]
port ovn-cluster-join
mac: "d2:21:17:71:77:70"
networks: ["100.64.0.1/16"]
port ovn-cluster-ovn-default
mac: "d6:a3:f5:31:cd:89"
networks: ["10.16.0.1/16"]
port ovn-cluster-subnet1
mac: "4a:09:aa:96:bb:f5"
networks: ["10.17.0.1/16"]
- 在 OVN Logical Router 上创建的 BFD Port。
2. 为 VPC Egress Gateway 启用 BFD
然后,通过将 .spec.bfd.enabled 设置为 true 来为 VPC Egress Gateway 启用 BFD:
apiVersion: kubeovn.io/v1
kind: VpcEgressGateway
metadata:
name: gateway2
namespace: default
spec:
vpc: ovn-cluster
replicas: 2
internalSubnet: ovn-default
externalSubnet: underlay-ext
externalIPs:
- 172.17.0.11
- 172.17.0.12
- 172.17.0.13
bfd:
enabled: true
minRX: 100
minTX: 100
multiplier: 5
policies:
- snat: true
ipBlocks:
- 10.18.0.0/16
- 该 Egress Gateway 所属的 VPC。
- Egress Gateway 实例连接的内部子网。
- Egress Gateway 实例连接的外部子网。
- 分配给 Egress Gateway 实例的外部 IP。
- 是否为 Egress Gateway 启用 BFD。
- BFD 的最小接收间隔,单位为毫秒。
- BFD 的最小发送间隔,单位为毫秒。
- BFD 的乘数,用于决定在判定故障之前允许丢失的报文数量。
此示例创建了一个名为 gateway2 的 VPC Egress Gateway,具有两个副本并启用了 BFD。
如果某个实例发生故障,BFD 会话将断开,OVN 会将路由标记为不可用,并将流量重定向到健康实例。
故障切换检测时间取决于 BFD 设置。
可使用以下公式:break time = (multiplier + 1) * max(minRX, minTX)。
在此示例配置下,故障切换检测时间约为 500-600 ms。
NOTE
故障切换期间,现有连接可能会中断并需要重新建立连接。新的连接仍可正常建立。
3. 验证 BFD 状态
检查 VPC Egress Gateway 状态:
$ kubectl get veg -n default gateway2 -o wide
NAME VPC REPLICAS BFD ENABLED EXTERNAL SUBNET PHASE READY INTERNAL IPS EXTERNAL IPS WORKING NODES AGE
gateway2 ovn-cluster 2 true underlay-ext Completed true ["10.16.0.12","10.16.0.13"] ["172.17.0.11","172.17.0.12"] ["node1","node2"] 58s
$ kubectl get pod -n default -l ovn.kubernetes.io/vpc-egress-gateway=gateway2 -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
gateway2-fcc6b8b87-8lgvx 1/1 Running 0 2m18s 10.16.0.13 node2 <none> <none>
gateway2-fcc6b8b87-wmww6 1/1 Running 0 2m18s 10.16.0.12 node1 <none> <none>
$ kubectl ko nbctl lr-policy-list ovn-cluster
Routing Policies
31000 ip4.dst == 10.16.0.0/16 allow
31000 ip4.dst == 10.17.0.0/16 allow
31000 ip4.dst == 100.64.0.0/16 allow
30000 ip4.dst == 172.18.0.2 reroute 100.64.0.4
30000 ip4.dst == 172.18.0.3 reroute 100.64.0.3
30000 ip4.dst == 172.18.0.4 reroute 100.64.0.2
29100 ip4.src == $VEG.8ca38ae7da18.ipv4 reroute 10.16.0.12, 10.16.0.13 bfd
29100 ip4.src == $VEG.8ca38ae7da18_ip4 reroute 10.16.0.12, 10.16.0.13 bfd
29090 ip4.src == $VEG.8ca38ae7da18.ipv4 drop
29090 ip4.src == $VEG.8ca38ae7da18_ip4 drop
29000 ip4.src == $ovn.default.kube.ovn.control.plane_ip4 reroute 100.64.0.3
29000 ip4.src == $ovn.default.kube.ovn.worker2_ip4 reroute 100.64.0.2
29000 ip4.src == $ovn.default.kube.ovn.worker_ip4 reroute 100.64.0.4
29000 ip4.src == $subnet1.kube.ovn.control.plane_ip4 reroute 100.64.0.3
29000 ip4.src == $subnet1.kube.ovn.worker2_ip4 reroute 100.64.0.2
29000 ip4.src == $subnet1.kube.ovn.worker_ip4 reroute 100.64.0.4
$ kubectl ko nbctl list bfd
_uuid : 223ede10-9169-4c7d-9524-a546e24bfab5
detect_mult : 5
dst_ip : "10.16.0.12"
external_ids : {af="4", vendor=kube-ovn, vpc-egress-gateway="default/gateway2"}
logical_port : "bfd@ovn-cluster"
min_rx : 100
min_tx : 100
options : {}
status : up
_uuid : b050c75e-2462-470b-b89c-7bd38889b758
detect_mult : 5
dst_ip : "10.16.0.13"
external_ids : {af="4", vendor=kube-ovn, vpc-egress-gateway="default/gateway2"}
logical_port : "bfd@ovn-cluster"
min_rx : 100
min_tx : 100
options : {}
status : up
然后检查 BFD 会话:
$ kubectl exec -n default gateway2-fcc6b8b87-8lgvx -c bfdd -- bfdd-control status
There are 1 sessions:
Session 1
id=1 local=10.16.0.13 (p) remote=10.255.255.255 state=Up
$ kubectl exec -n default gateway2-fcc6b8b87-wmww6 -c bfdd -- bfdd-control status
There are 1 sessions:
Session 1
id=1 local=10.16.0.12 (p) remote=10.255.255.255 state=Up
NOTE
如果所有网关实例都处于下线状态,由 VPC Egress Gateway 处理的出站流量将被丢弃。
可能中断流量的操作
以下操作可能会短暂中断出站流量,因为它们会删除或重建网关实例:
- 更改副本数量
- 更改配置,例如内部或外部 IP、node selectors 或 BFD 设置
- 在未指定 .spec.image 时升级或降级 Kube-OVN
- 手动删除 Egress Gateway Pod
其他资源