Alert Policies
您可以在 ASM 平台上自行创建自定义告警策略,也可以使用平台管理中管理员提供的模板快速创建告警策略。
创建个性化告警策略
基于平台的监控、日志和事件数据,结合平台的通知功能,为当前服务网格下同一命名空间中的服务和计算组件创建指标告警、自定义告警、日志告警和事件告警类型。当告警策略所针对的资源出现异常或监控数据达到预设的告警状态时,自动触发告警并发送通知。
前提条件
-
如果需要告警配置自动通知,请提前联系平台管理员,在 平台管理 视图中配置 通知策略。
-
确保告警策略所针对资源所在的集群已部署监控组件,以使基于监控指标创建的告警策略生效。
-
确保告警策略所针对资源所在的集群已部署 Elasticsearch 组件,以使基于日志和事件查询结果创建的告警策略生效。
快速开始
-
在左侧导航栏点击 Alerts > Rules。
-
点击 Create Rule。
基本信息
在 基本信息 区域,配置告警策略的基本信息。首先需要选择不同类型的告警。
资源告警
根据监控资源类别划分的告警类型,例如以下两种场景:
- 持续监控当前命名空间下部分或全部 Deployment,当其部署状态非 Running 时触发告警。
- 持续监控当前命名空间下某个特定微服务,当其服务流量错误率超过 20% 时触发告警。
提示:
- 如果资源对象中未选择相关参数,默认为 Any。后续资源对象的 删除/新增 会导致告警策略的 解除关联/自动关联。
- Services 为可选项,也可以通过输入并回车指定。输入时支持使用正则表达式匹配服务名称,如
cert.*。
事件告警
根据 K8s 事件划分的告警类型,例如以下场景:
针对当前命名空间下名为 Nginx 的 Pod,添加匹配规则后,当 Pod 状态为 Failed 时触发告警。
提示:如果匹配规则未选择,则默认选择某资源下的所有资源,后续资源的 删除/新增 会导致告警策略的 解除关联/自动关联。
快速提示
如果希望持续监控 OpenTelemetry 服务,请选择 资源告警 并将治理方式选择为 OpenTelemetry。
告警规则
选择告警类型并根据上述说明设置监控范围后,即可添加对应的告警规则。
资源告警
-
在 规则 区域,点击 添加告警规则。
注意:对话框上方显示的监控图表提供监控指标或表达式的数据预览,会根据选择实时变化。您可以根据图表重新确认输入内容。

-
选择告警类型,并参考以下说明配置告警规则。
指标告警:选择平台预设的告警指标。
自定义告警
请参考以下说明填写相关数据:
- 指标名称:输入当前自定义指标的名称,便于管理和检索。
- 表达式:根据监控场景添加具体的指标规则,以满足高级监控和告警需求。需手动输入 Prometheus 可识别的指标和监控表达式,如:
rate(node_network_receive_bytes{instance="$server",device!~"lo"}[5m])。 - 单位:监控指标的单位,可手动输入自定义单位。
- 图例参数:为方便图例中数据的显示和查看,可输入监控数据的标签作为 key,对应的
value作为图例标识。输入格式为:{{.key}}。
图例参数设置说明:输入正确表达式后,将鼠标移至对话框上方监控图表右侧的排名统计列表记录处,可查看数据的所有标签。如图所示。
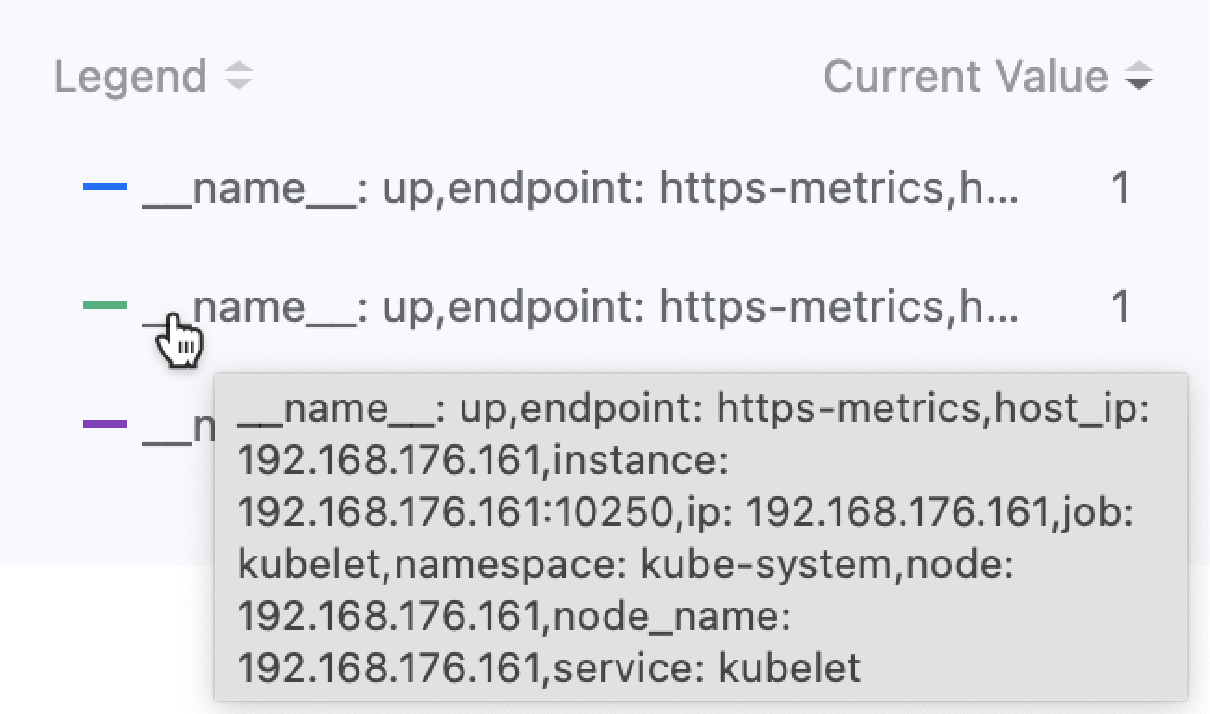
例如:通过表达式 up{service="kubelet"} 获取的监控数据标签包括 "__name__":"up","endpoint":"https-metrics","instance":"192.168.18.2:10250","job":"kubelet","namespace":"kube-system","node":"192.168.18.2","service":"kubelet"。若想使用采集数据的目标端点作为图例标识,可输入图例参数 {{.instance}}。显示效果如下图所示。
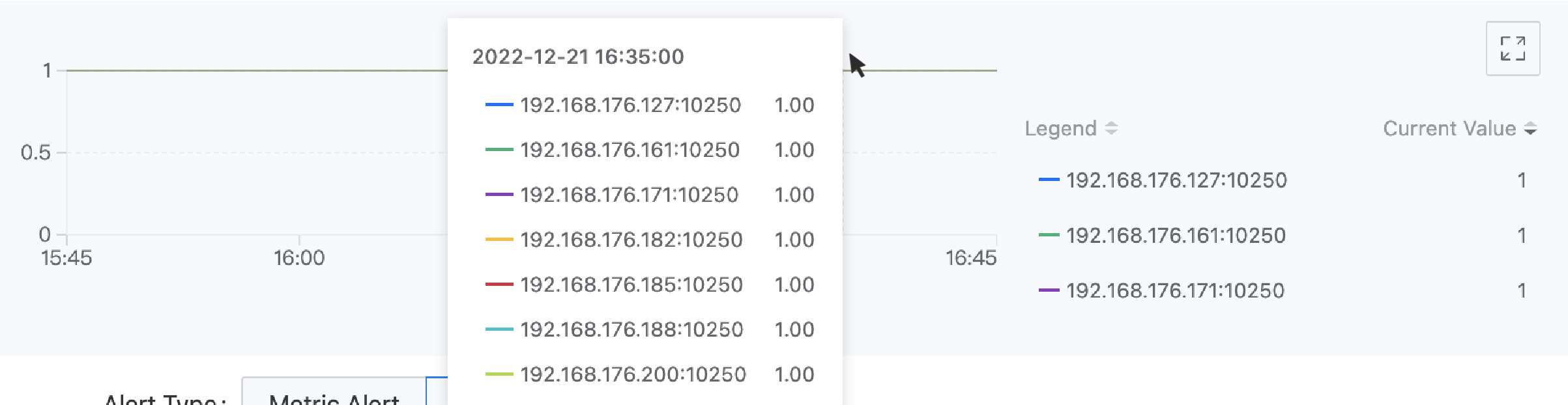
- 输入触发条件
触发条件 由比较运算符、告警阈值和持续时间(可选)组成。监控指标的实时值/日志计数/事件计数与告警阈值的比较结果,以及实时值持续处于告警阈值范围的时间长度,决定是否触发告警。
比较运算符:>(大于)、>=(大于等于)、==(等于)、<=(小于等于)、<(小于)、!=(不等于)。
阈值:告警阈值仅接受数字。当选择的黑盒监控项的 检测方式 为 HTTP 且 指标名称 选为 cluster.blackbox.http.status.code 时,告警阈值为 HTTP 请求返回状态码,仅支持输入三位正整数,如:200。
持续时间:指标数据实时值持续处于告警阈值范围的时间长度,达到指定时间后触发告警。
- 选择告警级别
告警规则的告警级别由用户设置,允许用户根据告警规则对应资源对业务运营的影响合理设置告警级别。
Critical:告警规则对应资源故障导致平台业务中断、数据丢失,影响重大。例如:节点健康状态值为 0(宕机)持续 3 分钟。
High:告警规则对应资源存在已知问题,可能导致平台功能故障,影响正常业务运营。例如:计算组件可用 Pod 组数为 0 持续 3 分钟。
Medium:告警规则对应资源存在运行风险,若未及时处理,可能影响正常业务运营。例如:节点 CPU 使用率超过 80% 持续 3 分钟。
Low:告警规则对应资源存在预期问题,短期内不影响业务运营,但存在潜在风险。例如:节点 CPU 使用率超过 70% 持续 3 分钟。
- 点击 添加。
事件告警
-
选择 事件告警 作为告警类型后,在 规则 区域点击 添加告警规则。
-
选择时间范围。例如:时间范围设置为 5 分钟,告警创建后,任意 5 分钟内满足条件的事件数量达到阈值即触发告警。
-
事件监控项
监控所选事件的事件级别或事件原因。
- 事件严重性:所选事件定义的严重级别,如 Warning。
- 事件原因:事件的具体原因(Reason,如 BackOff、Pulling、Failed 等),确认时按回车键。可输入多个字段,查询时多个字段之间关系为
or,即包含任一指定事件原因的记录均符合查询条件。
-
触发条件
触发条件使用比较运算符,根据事件记录数量的比较结果判断是否告警。
-
告警级别
告警规则的告警级别由用户设置,允许用户根据告警规则对应资源对业务运营的影响合理设置告警级别。
Critical:告警规则对应资源故障导致平台业务中断、数据丢失,影响重大。例如:节点健康状态值为 0(宕机)持续 3 分钟。
High:告警规则对应资源存在已知问题,可能导致平台功能故障,影响正常业务运营。例如:计算组件可用 Pod 组数为 0 持续 3 分钟。
Medium:告警规则对应资源存在运行风险,若未及时处理,可能影响正常业务运营。例如:节点 CPU 使用率超过 80% 持续 3 分钟。
Low:告警规则对应资源存在预期问题,短期内不影响业务运营,但存在潜在风险。例如:节点 CPU 使用率超过 70% 持续 3 分钟。
-
点击 添加。
结果验证
无论选择自定义告警还是事件告警,添加完成后弹窗关闭,您添加的条目会显示在创建告警策略页面的 规则 列表中。
通知策略配置(可选)
如果您已在管理页面创建通知策略,可在 策略配置 区域设置告警触发后的通知动作。
-
点击 通知策略 下拉框,选择平台上已创建的一个或多个通知策略。
-
选择 告警通知间隔,配置从告警触发到恢复正常期间发送告警消息的间隔。
-
全局:选择使用平台的全局默认配置。全局配置支持更新。
-
自定义:选择 自定义 后,可点击告警级别旁的下拉框调整发送告警消息的间隔。
注意:选择 不重复 时,告警触发和恢复时各发送一条告警消息。
完成
确认输入信息无误后,点击 创建 完成操作。您可以在告警策略列表中管理并查看每条策略的当前状态(如是否触发告警)。
使用告警策略模板创建告警策略
使用平台上创建的告警模板,快速为指定计算组件创建告警策略。
前提条件
-
管理员已在平台创建计算组件的告警模板(平台管理视图 > 运营中心 > 告警 > 告警模板)。
-
确保告警策略所针对资源所在的集群已部署监控组件,以使基于监控指标创建的告警策略生效。
-
确保告警策略所针对资源所在的集群已部署 Elasticsearch 组件,以使基于日志和事件查询结果创建的告警策略生效。
步骤
- 在左侧导航栏点击 Alerts > Rules。
- 点击 Create Rule 按钮旁的
 > From Template。
> From Template。 - 配置告警策略的基本信息,选择 资源对象 和 所属集群。
- 点击 创建。
后续操作
查看实时告警
您可以在告警策略列表中查看已创建告警策略的当前告警状态。
此外,为了更清晰地展示当前告警情况,平台提供了 实时告警 面板功能,集中展示当前发生告警的资源、告警影响等级及详细告警信息,范围涵盖您有权限的当前服务网格下各集群。这方便运维人员和开发人员实时掌握平台整体业务告警情况,及时排查故障因素,保障平台正常运行。
禁用/启用告警规则
为方便灵活管理策略下的规则,支持对已创建告警策略中的规则进行禁用/启用操作。禁用后,规则状态变为 -,且不计入告警策略规则总数;重新启用后,规则中包含的告警触发条件重新生效。
步骤
-
在左侧导航栏点击 Alerts > Rules。
-
点击要管理的规则的 名称。
-
在 告警条件 区域,点击规则旁的 禁用/启用 开关进行操作。